Introduction:
In “Risk Management”, zero risk is impossible. No matter how well we build, determined attackers will find a way in.
The question isn’t if an incident will occur, but how we respond when it does.
Reading about the critical lifecycle of Incident Response (IR) and Incident Management (IM), it taught me that a fast, organized response can mean the difference between a minor glitch and a catastrophic breach.
1. Intro to IR and IM
Before diving into tools, I had to understand the difference between Incident Response (the technical act of handling the breach) and Incident Management (the organizational process of coordinating the response).
Key Concepts:
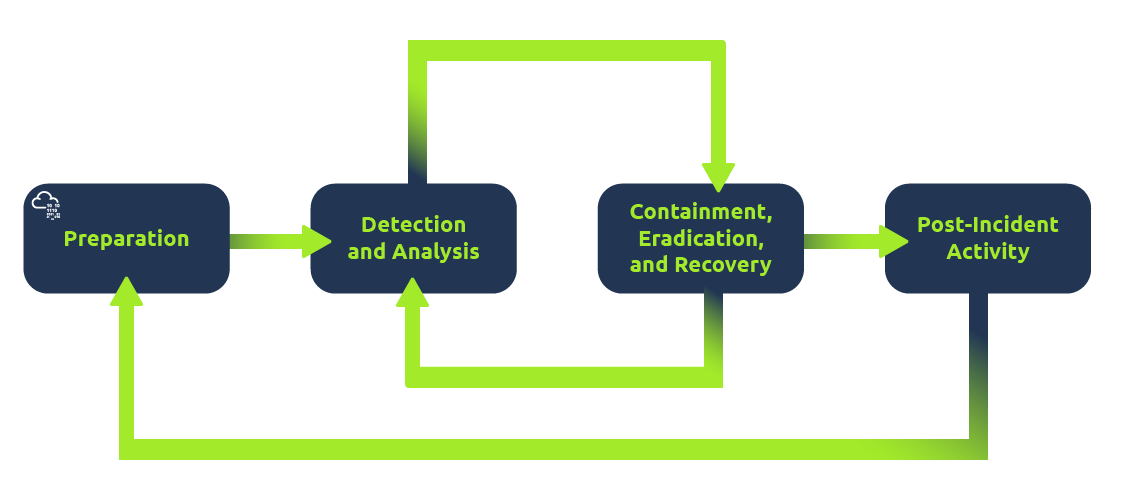
- The NIST Lifecycle: the standard four-phase approach:
- Preparation: Having the plan, tools, and team ready before an attack.
- Detection & Analysis: Identifying the incident and determining its scope.
- Containment, Eradication, & Recovery: Stopping the bleeding, removing the threat, and restoring systems.
- Post-Incident Activity: The “lessons learned” phase to prevent recurrence.
- The Role of the Security Engineer: In an incident, this role isn’t just to fix the server; it’s to preserve evidence, communicate with stakeholders, and ensure the root cause is addressed.
2. Logging for Accountability
You cannot investigate what you cannot see. The importance of logging not just for debugging, but for forensics and accountability.
- What to Log: It’s not enough to log “errors.” We need to log authentication attempts, privilege escalations, file access, and network connections.
- Centralization: Logs scattered across individual servers are useless during an attack. They must be sent to a centralized, tamper-proof location (like a SIEM) immediately.
- Time Synchronization: If clocks aren’t synchronized (via NTP), correlating events across different systems becomes a nightmare.
- Chain of Custody: Understanding how to handle logs as legal evidence is crucial. If the chain is broken, the evidence might be inadmissible in court.
3. Becoming a First Responder
Being a First Responder means being the first person on the scene when the fire alarm rings. It requires calmness, procedure, and speed.
The First Responder Checklist:
- Verify the Alert: Is it a false positive or a real breach? Don’t panic, but don’t ignore it.
- Preserve Evidence: Before touching anything, capture memory dumps, disk images, and network traffic. Do not reboot the system unless absolutely necessary, as it destroys volatile data.
- Containment Strategies:
- Isolation: Disconnect the infected machine from the network (pull the plug or disable the NIC).
- Segmentation: Block traffic at the firewall level to stop lateral movement.
- Communication: Who do you tell? Legal? HR? Management? The “Who, What, When, Where” communication chain is vital.
4. Cyber Crisis Management
Sometimes, an incident escalates into a full-blown Crisis. This is where technical skills meet leadership and communication.
Crisis Management Principles:
- Decision Making Under Pressure: In a crisis, you don’t have perfect information. You must make the best decision possible with the data at hand.
- Stakeholder Management: Executives care about reputation and downtime; Legal cares about liability; Customers care about their data. A Security Engineer must translate technical chaos into business impact.
- The War Room: Establishing a dedicated communication channel (physical or virtual) where the incident commander leads the response.
- Ransomware Specifics: learn the specific protocols for ransomware: do not pay (usually), isolate immediately, and engage law enforcement.
Conclusion:
I now understand that security is not a static state of “being safe.” It is a dynamic cycle of:
- Preventing what we can.
- Detecting what slips through.
- Responding effectively when it happens.
- Learning to be better next time.
Being a Security Engineer means accepting that breaches will happen. But it also means having the confidence that when they do, we are ready. We have the logs, the playbooks, the skills, and the mindset to turn a potential disaster into a manageable event.
This is a reminder that technology is only part of the equation. People, processes, and preparation are the true backbone of incident management.